

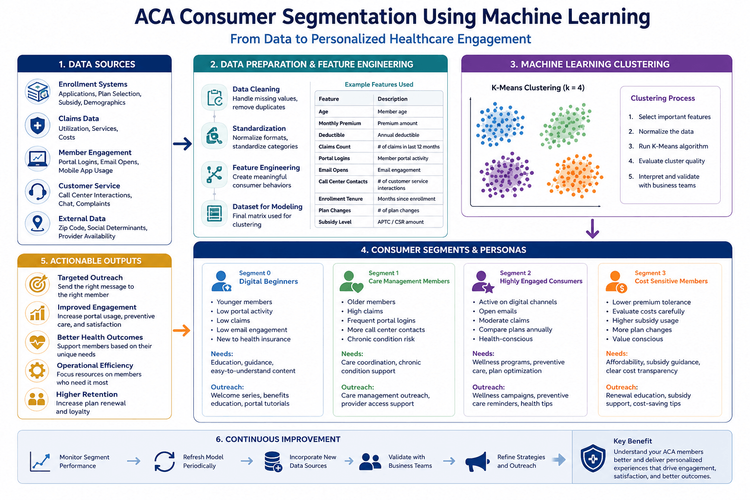
Introdução
O Affordable Care Act (ACA) transformou o seguro saúde num mercado orientado para o consumidor, onde milhões de americanos comparam planos, avaliam custos e tomam decisões de cobertura todos os anos.
Para os planos de saúde, o desafio não é mais simplesmente cadastrar os associados – é compreendê-los.
A análise tradicional responde a perguntas como:
- Quantos membros se inscreveram este mês?\
- Quais condados tiveram o maior crescimento?\
- Qual foi a taxa de retenção geral?
Essas métricas são úteis, mas tratam toda a população como um único grupo.
Na realidade, os consumidores da ACA têm comportamentos, preferências de comunicação, padrões de utilização de cuidados de saúde e considerações financeiras muito diferentes.
Um jovem de 28 anos inscrito pela primeira vez pode necessitar de educação sobre cuidados preventivos, enquanto uma família que gere condições crónicas pode necessitar de coordenação de cuidados e apoio farmacêutico.
Em vez de enviar campanhas de divulgação idênticas a todos os membros, as organizações de saúde podem utilizar a aprendizagem automática para identificar automaticamente grupos de consumidores com características semelhantes e proporcionar experiências mais personalizadas.
Neste tutorial, construiremos um modelo simples de segmentação de consumidores usando Python e Scikit-Learn.
Suponha que um plano de saúde da ACA tenha 500.000 membros.
Enviar o mesmo e-mail para todos os membros raramente é eficaz.
Em vez disso, a organização deseja identificar:
- Consumidores que priorizam o digital\
- Compradores sensíveis aos custos\
- Grandes usuários de serviços de saúde\
- Integrantes que raramente se envolvem com o plano de saúde\
- Consumidores que podem precisar de educação adicional
O aprendizado de máquina nos permite descobrir esses grupos sem defini-los manualmente.
Suponha que temos as seguintes variáveis coletadas de sistemas de inscrição, portais de membros e plataformas de engajamento.
| Variável | Descrição |
| ——————– | —————————– |
| Idade | Idade do membro |
| Prêmio Mensal | Montante do prémio mensal |
| Franquia | Franquia anual |
| Contagem de reclamações | Número de pedidos apresentados |
| Logins do Portal | Uso do portal de membros |
| Abertura de e-mail | Engajamento de marketing |
| Contactos do Call Center | Interações de atendimento ao cliente |
import pandas as pd
data = {\
"member_id":(1001,1002,1003,1004,1005,1006,1007,1008),\
"age":(28,45,62,31,54,39,27,58),\
"premium":(120,35,20,280,75,210,15,60),\
"deductible":(6500,2500,500,7000,1200,5000,0,1000),\
"claims":(1,8,16,0,10,3,5,14),\
"portal_logins":(2,12,18,1,9,4,7,15),\
"email_opens":(3,15,20,1,10,5,6,18),\
"call_center":(0,2,5,1,4,1,2,6)\
}
df = pd.DataFrame(data)
print(df.head())\
Saída:
member_id age premium deductible claims portal_logins ...\
1001 28 120 6500 1 2\
1002 45 35 2500 8 12\
...\
As variáveis de saúde existem em diferentes escalas.
Os valores premium podem variar de 0 a 500, enquanto os logins do portal variam de 0 a 20.
Sem normalização, valores maiores dominam o algoritmo de agrupamento.
from sklearn.preprocessing import StandardScaler
features = (\
"age",\
"premium",\
"deductible",\
"claims",\
"portal_logins",\
"email_opens",\
"call_center"\
)
X = df(features)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)\
Dividiremos a população em quatro segmentos de consumidores.
from sklearn.cluster import KMeans
model = KMeans(\
n_clusters=4,\
random_state=42,\
n_init=10\
)
df("consumer_segment") = model.fit_predict(X_scaled)\
Veja os resultados:
print(df(\
(\
"member_id",\
"consumer_segment"\
)\
))\
Exemplo de saída:
member_id consumer_segment
1001 0\
1002 2\
1003 1\
1004 0\
1005 3\
O aprendizado de máquina cria os grupos.
Os analistas de saúde interpretam o que eles significam.
summary = df.groupby(\
"consumer_segment"\
)(features).mean()
print(summary)\
Exemplo de saída:
| Segmento | Características |
| ——— | ———————————————————— |
| Segmento 0 | Jovem, baixo envolvimento, baixa utilização |
| Segmento 1 | Usuários mais antigos e exigentes do portal |
| Segmento 2 | Utilização moderada, envolvimento digital |
| Segmento 3 | Uso frequente e consciente dos custos do atendimento ao cliente |
Estas não são categorias predefinidas.
Eles emergem naturalmente dos dados.
O aprendizado de máquina produz números.
As equipes de negócios precisam de insights acionáveis.
segment_name = {\
0:"Digital Beginners",\
1:"Care Management Members",\
2:"Highly Engaged Consumers",\
3:"Cost Sensitive Members"\
}
df("consumer_persona") = df(\
"consumer_segment"\
).map(segment_name)\
Agora, cada membro pertence a uma personalidade favorável aos negócios.
| Membro | Pessoa |
| —— | ———————— |
| 1001 | Iniciantes Digitais |
| 1002 | Consumidores altamente engajados |
| 1003 | Membros da Gestão de Cuidados |
Em vez de enviar campanhas idênticas, podemos automatizar recomendações.
def outreach_strategy(persona):
if persona == "Digital Beginners":\
return "Send benefit education and portal tutorials"
if persona == "Care Management Members":\
return "Assign care management outreach"
if persona == "Highly Engaged Consumers":\
return "Promote wellness and preventive services"
if persona == "Cost Sensitive Members":\
return "Provide subsidy and renewal guidance"
df("recommended_action") = df(\
"consumer_persona"\
).apply(outreach_strategy)\
Resultado:
| Membro | Pessoa | Ação recomendada |
| —— | ———————— | ———————— |
| 1001 | Iniciantes Digitais | Beneficiar educação |
| 1002 | Consumidores altamente engajados | Campanha de bem-estar |
| 1003 | Membros da Gestão de Cuidados | Extensão em gestão de cuidados |
Essa abordagem permite que as organizações de saúde vão além dos painéis estáticos e dos simples relatórios de inscrição.
Em vez de perguntar:
Quantos membros se inscreveram este mês?
As organizações podem perguntar:
Quais membros têm maior probabilidade de se beneficiar da educação sobre cuidados preventivos?
Quais consumidores precisam de suporte adicional durante a renovação?
Qual população prefere o envolvimento digital em vez do alcance do call center?
A segmentação do consumidor fornece uma maneira escalonável de responder a essas perguntas.
Uma implementação de produção normalmente incluiria:
- Extração de dados SQL de sistemas de inscrição\
- Pipelines de engenharia de recursos do Python\
- Atualizações automatizadas de clustering\
- Painéis do Tableau para usuários corporativos\
- Revisão humana de personas de consumidores\
- Monitoramento contínuo conforme o comportamento dos membros muda
As organizações de saúde também devem avaliar os resultados da segmentação quanto à justiça, transparência e relevância comercial, garantindo que o aprendizado de máquina apoie – e não substitua – a tomada de decisões humanas.
O futuro da análise da ACA está mudando do relato de médias populacionais para a compreensão das necessidades individuais dos consumidores.
Ao combinar dados de inscrição, métricas de engajamento e aprendizado de máquina, os analistas podem identificar segmentos de consumidores significativos e fornecer estratégias de divulgação mais personalizadas.
O objetivo não é simplesmente classificar os membros em clusters, mas transformar os dados de saúde em insights acionáveis que melhorem a experiência dos membros, aumentem o envolvimento e ajudem os consumidores a fazer melhor uso da sua cobertura de saúde.
